llama.cpp MTP-Support : Modèles locaux 27B 1,7 fois plus rapides sur les GPU grand public
La PR 22673 intègre la prédiction multi-tokens (Multi-Token Prediction) dans la branche principale de llama.cpp.
7 min. de lecture
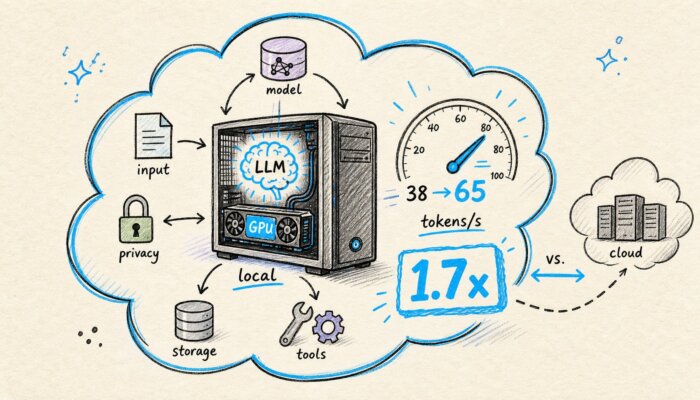
Le 16 mai 2026, la PR #22673 a été fusionnée dans llama.cpp. La prédiction multi-token fonctionne depuis lors dans la branche principale. Sur une RTX 3090, Qwen3.6 27B passe ainsi de 38 à 65 tokens par seconde, soit environ 1,7x plus rapide. Ce n’est pas une nouvelle de type hyperscaler, mais cela
Ce que le facteur 1,7x signifie en pratique
La marque 1,7x, souvent citée, provient d’un benchmark RunPod avec Qwen3.6 27B sur une RTX 3090. Sans MTP, la configuration délivre 38 tokens par seconde en single-stream. Avec le MTP-Head activé, elle atteint 65. Cela représente une différence de 27 tokens par seconde. Elle fait la différence entre une interaction localement agréable et une autre qui traîne comme
Réalité matérielle entre 3090, 4090, 5090 et H100
La question passionnante n’est pas de savoir si le MTP a encore un effet sur une H100. La réponse est, comme on peut s’y attendre, moins spectaculaire. La question passionnante est de savoir où se situe le seuil à partir duquel un GPU grand public avec MTP peut sérieusement être considéré comme un substitut d’inférence pour une heure d’
Foire aux questions
Qu’est-ce que la prédiction multi-jetons dans llama.cpp concrètement ?
La MTP est une forme de décodage spéculatif où une tête de sortie supplémentaire, directement intégrée au modèle principal, propose plusieurs jetons simultanément. Le modèle principal les vérifie lors du prochain passage avant et les accepte ou les rejette. Contrairement au décodage spéculatif classique, aucun second modèle
