Wie funktioniert eigentlich ein Betriebssystem?
Du drückst auf den Power-Button und Sekunden später bewegt sich dein Cursor. Was dazwischen passiert, ist die meistunterschätzte Software der Welt - und genau das, worauf jeder Pod, jeder Container und jede …

Du drückst auf den Power-Button und Sekunden später bewegt sich dein Cursor. Was dazwischen passiert, ist die meistunterschätzte Software der Welt – und genau das, worauf jeder Pod, jeder Container und jede Cloud-VM aufsetzt.
Das Wichtigste in Kürze
- Vom Power-Button zum Kernel sind es vier Stages: Firmware (UEFI) startet den Bootloader, der lädt den Kernel in den RAM, der Kernel schaltet die CPU in den geschützten Modus und baut sich seine Welt selbst. Bis hierhin existieren weder Dateien noch Prozesse.
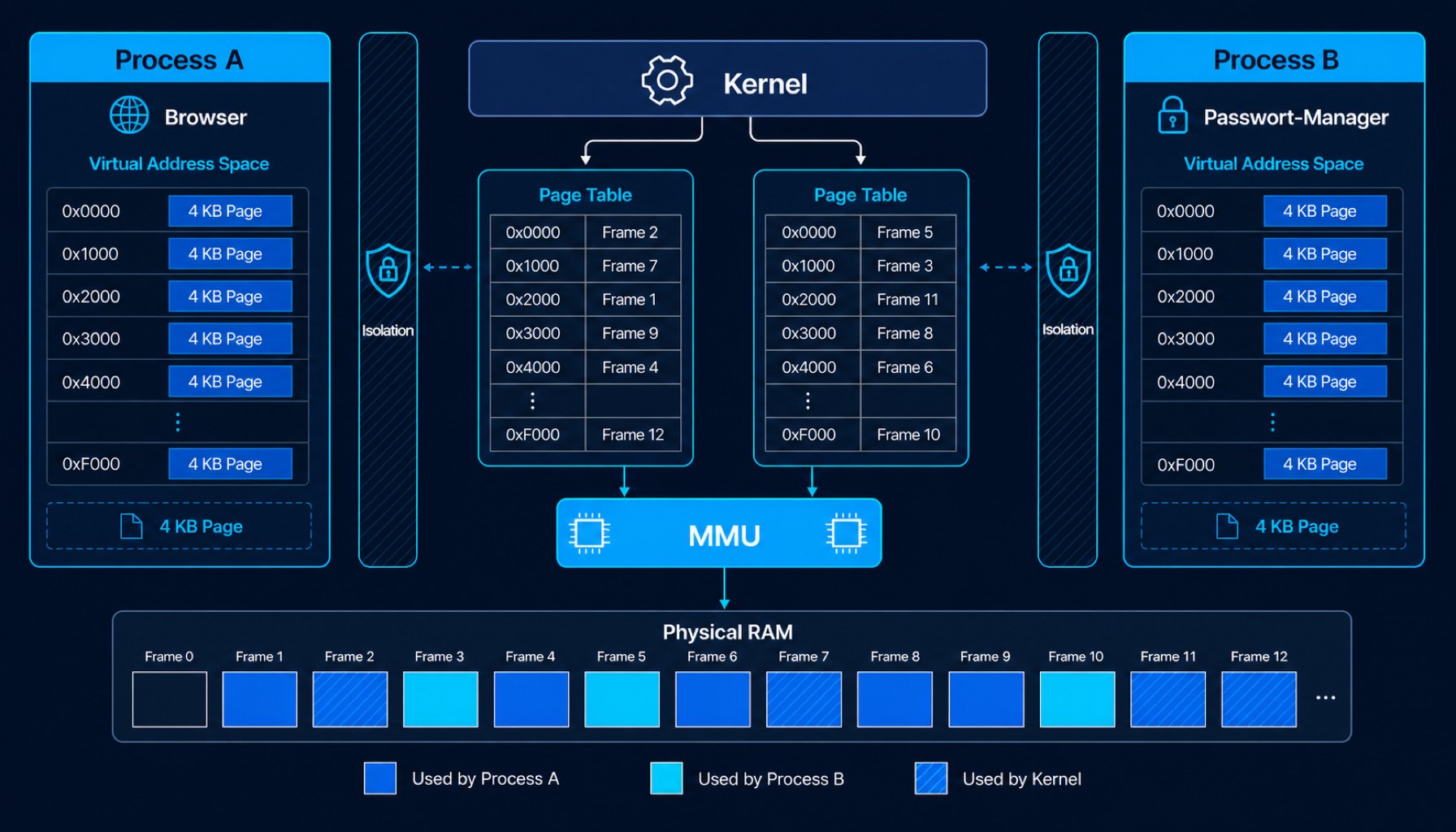
- Virtual Memory ist die größte Lüge im Computing: Jedes Programm sieht seinen eigenen Adressraum, die MMU übersetzt im Hintergrund auf echtes RAM. Genau diese Lüge macht Container-Isolation und Memory-Limits in cgroups erst möglich.
- Scheduler, Syscalls und IPC sind die Cloud-Grundlagen, die niemand erklärt: Der Linux-Scheduler verteilt Prozesse auf CPU-Kerne, der Kubernetes-Scheduler verteilt Pods auf Nodes – derselbe Mechanismus eine Ebene höher.
Verwandt:Kubernetes 1.31 Sidecar Containers / Container-Runtime im Vergleich
Strom an: Bootloader und Privilege Rings
Ein Betriebssystem ist kein einzelnes Programm, sondern eine choreografierte Abfolge von zehn Stages. Wer Container debuggt oder Kubernetes-Cluster plant, arbeitet jeden Tag mit dem Ergebnis – meist ohne zu wissen, was im Maschinenraum passiert.
Du drückst den Power-Button. Strom geht an die Hauptplatine, die CPU wacht auf und führt den allerersten Befehl an einer fest verdrahteten Adresse aus. An diesem Punkt gibt es weder Speicherverwaltung noch Dateien – nur einen einzelnen Kern, der eine Firmware ausführt. Auf modernen Rechnern heißt sie UEFI, früher war es BIOS.
Die Firmware weckt gerade so viel Hardware auf, dass sie eine Festplatte findet und übergibt dann an den Bootloader: Grub auf Linux, iBoot auf Mac, Boot Manager auf Windows. Der Bootloader hat genau eine Aufgabe – den Kernel in den RAM zu laden. Sobald das passiert ist, läuft die CPU in Ring 0, dem Modus mit voller Hardware-Kontrolle.
Ring 0 vs. Ring 3 ist die wichtigste Trennlinie deines Computers. x86-CPUs haben vier Ringe, aber praktisch zählen nur zwei: Ring 0 für den Kernel, Ring 3 für alles Andere. Ein Bug in Ring-0-Code legt die ganze Maschine lahm – der berühmte Crowdstrike-Ausfall im Sommer 2024 war genau das: ein fehlerhafter Treiber in Ring 0, der weltweit Windows-Maschinen in den Bluescreen gerissen hat.
Die größte Lüge im Computing: Virtual Memory
Wenn ein Programm eine Speicheradresse anfordert, ist diese Adresse fast immer eine Lüge. Sie ist eine virtuelle Adresse, die eine Hardware-Komponente namens MMU (Memory Management Unit) erst in eine echte physische Adresse übersetzt. Die Übersetzung passiert über eine Datenstruktur namens Page Table, die der Kernel pro Prozess pflegt. Speicher wird in 4-Kilobyte-Pages ausgeliefert, jeder Prozess bekommt seinen eigenen virtuellen Adressraum.
Genau diese Trennung ist der Grund, warum dein Browser nicht im Speicher deines Passwort-Managers herumlesen kann. Beide leben in parallelen Universen, die nur der Kernel überblickt.
Die MMU cached häufige Übersetzungen in einem winzigen Buffer, dem TLB. Greift ein Prozess auf eine Page zu, die nicht im RAM liegt, feuert die MMU einen Page Fault, der Kernel lädt die Page von der Festplatte nach und der Prozess läuft weiter, als wäre nichts gewesen. Genau dieser Mechanismus ist die Grundlage von Container-Memory-Limits: Wenn ein Pod sein cgroup-Limit überschreitet, kommt der OOM-Killer und schießt den Prozess ab – kein Swap, kein Warnen.
Treiber, Interrupts und der erste Prozess
Sobald der Kernel Speicher und Dateisystem kennt, lädt er Treiber. Treiber übersetzen generische Kernel-Anfragen in chip-spezifische Befehle für GPU, WLAN-Karte, Tastatur. Sie laufen in Ring 0, was bequem für Performance, aber gefährlich für Stabilität ist. Der erwähnte Crowdstrike-Vorfall ist die Industrie-Erinnerung daran, warum Treiber-Reviews ernst genommen werden müssen.
Mit den Treibern aktiviert der Kernel Interrupts. Wie weiß ein Betriebssystem, dass du gerade eine Taste gedrückt hast? Es fragt nicht in einer Endlosschleife nach. Stattdessen feuert die Tastatur ein elektrisches Signal, das die CPU aus ihrer aktuellen Aufgabe reißt und in einen Interrupt-Handler im Kernel springen lässt. Jede Mausbewegung, jedes WLAN-Paket, jede Festplatten-Antwort ist ein Interrupt.
Erst jetzt erzeugt der Kernel den ersten User-Space-Prozess: PID 1, auf modernem Linux meist systemd. PID 1 ist der Urahn aller anderen Prozesse – stirbt PID 1, panickt der Kernel und der Rechner geht runter. Ab diesem Moment läuft alles in Ring 3 und muss den Kernel via System Calls um Erlaubnis fragen, wann immer es ans Dateisystem, ans Netzwerk oder an Hardware will.
Multitasking auf acht Kernen für hunderte Prozesse
Eine moderne Cloud-VM hat vielleicht acht oder sechzehn vCPUs, aber hunderte Prozesse. Damit das funktioniert, gibt es den Scheduler. Er entscheidet im Millisekunden-Takt, welcher Prozess gerade auf welchem Kern läuft. Der aktuelle Linux-Scheduler heißt EEVDF (Earliest Eligible Virtual Deadline First) und garantiert jedem Prozess seinen fairen CPU-Anteil.
Wenn du in Kubernetes kubectl get pods tippst, läuft im Hintergrund derselbe Mechanismus eine Ebene höher: Der Kubernetes-Scheduler verteilt Pods auf Nodes, ähnlich wie der Linux-Scheduler Prozesse auf Kerne verteilt. Resource Requests und Limits in K8s sind die Geschwister von nice-Werten und cgroup-Quotas auf OS-Ebene.
Innerhalb eines Prozesses läuft oft mehr als ein Pfad – über Threads. Threads teilen sich Speicher, haben aber eigene Stacks. Das ist mächtig, aber gefährlich: Schreiben zwei Threads gleichzeitig auf dieselbe Variable, entstehen Race Conditions. Moderne Sprachen versuchen das zu verhindern, Go über Goroutinen mit Channels, Rust über den Borrow Checker, der nicht-thread-sicheren Code schon beim Kompilieren ablehnt.
Wenn zwei komplett separate Prozesse miteinander reden müssen, hilft IPC – Interprozess-Kommunikation. Die einfachste Form ist die Pipe, erfunden 1973 von Doug McIlroy bei Bell Labs und bis heute ungeschlagen: cat log.txt | grep ERROR ist genau das. Daneben gibt es Sockets und Message Queues – die ganze Microservice-Architektur ist konzeptionell IPC, nur über das Netzwerk gespannt.
Was Cloud-Engineers daraus mitnehmen
Ein Container ist kein eigenes Betriebssystem. Er ist ein Userspace-Prozess auf einem Host-Kernel, isoliert über Namespaces und in Ressourcen begrenzt über cgroups. Genau deshalb starten Container in Millisekunden statt in Sekunden wie eine VM – das eigentliche OS läuft schon. Wer das einmal verstanden hat, debuggt OOMKilled-Pods, latenzkritische Workloads und Sidecar-Architekturen mit komplett anderem Blick.
Das Fireship-Video „Every operating system concept in one video“ liefert die zehn Stages in elf Minuten – als visueller Crashkurs eine sehr gute Ergänzung. Tiefer einsteigen lohnt sich über die Linux Kernel Documentation und die Klassiker-Lektüre „Operating Systems: Three Easy Pieces“ von Remzi Arpaci-Dusseau, frei verfügbar online. Wer die Sicherheits-Implikationen von Ring-0-Treibern vertiefen will, findet im SecurityToday-Schwesterportal die Analyse, wie KI-Agenten Linux-Kernel-Zero-Days finden.
Häufige Fragen
Brauche ich OS-Wissen, wenn ich nur Kubernetes nutze?
Spätestens beim ersten OOMKilled-Pod, beim ersten CPU-Throttling oder beim ersten Sidecar-Logging-Bug schon. Kubernetes abstrahiert das Betriebssystem nicht weg, es legt sich darüber. Resource Limits, Liveness Probes und Network Policies kannst du nur dann sinnvoll setzen, wenn du verstehst, wie cgroups, Namespaces und der Linux-Scheduler darunter arbeiten.
Sind Container leichter als VMs, weil sie kein Betriebssystem haben?
Container haben sehr wohl ein Betriebssystem – sie teilen sich nur den Kernel des Hosts. Was im Container-Image liegt, ist Userspace: Bibliotheken, Binaries, Konfiguration. Eine VM bringt einen kompletten eigenen Kernel mit, plus Hypervisor-Overhead. Das ist der Hauptgrund, warum Container in Millisekunden starten und VMs in Sekunden.
Warum killt Linux meinen Container, statt Swap zu nutzen?
Weil cgroups harte Memory-Limits durchsetzen. Sobald ein Container sein Limit überschreitet, schickt der OOM-Killer ein SIGKILL – ohne Vorwarnung, ohne Swap-Versuch. Das ist Absicht: Predictable Performance ist im Cluster wichtiger als best-effort-Überleben einzelner Pods. Wer das umgehen will, muss entweder Limits erhöhen oder Memory-Profiling betreiben.
Was ist der Unterschied zwischen Kernel- und User-Space?
Der Kernel-Space läuft in Ring 0 mit voller Hardware-Kontrolle. Hier liegen Treiber, der Scheduler, das Dateisystem-Modul. Der User-Space läuft in Ring 3, ohne direkten Hardware-Zugriff. Jeder Webserver, jede Datenbank, jeder Container läuft im User-Space. Will er auf Hardware oder Dateien zugreifen, geht das nur über System Calls – die einzige Brücke zwischen den beiden Welten.
Was passiert eigentlich beim Shutdown?
Andersherum als beim Start: PID 1 schickt jedem Prozess ein SIGTERM (höfliche Bitte, sich zu beenden). Wer nicht reagiert, bekommt nach Timeout SIGKILL. Dann flushen die Dateisysteme ihre Journale, Treiber geben Hardware frei, der Kernel synchronisiert den Speicher auf die Platte, deaktiviert Interrupts und die Firmware kappt kappt den Strom. Das alles in unter zwei Sekunden auf einer normalen Maschine.
Bildquelle: KI-generiert (Mai 2026), C2PA-Zertifikat im Bild hinterlegt
