Avant la Computex : Huang rencontre TSMC, AMD investit 10 milliards de dollars à Taïwan
Nvidia's Huang rencontre TSMC, AMD's Su investit 10 milliards dans l'emballage taïwanais, important pour l'approvisionnement en GPU et les architectes…
6 min de lecture
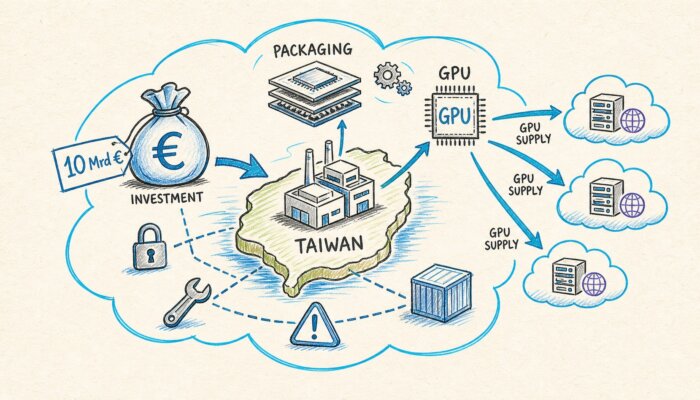
Jensen Huang, PDG de Nvidia, a atterri à Taïpeh le samedi 24 mai, huit jours avant sa keynote GTC du 1er juin et parallèlement à une étape chez TSMC, dont dépend la montée en puissance de Vera Rubin. Quatre jours plus tôt, le 20 mai, Lisa Su, PDG d’AMD, s’était également rendue dans la même ville, accompagnée d’un communiqué de presse : plus de 10 milliards de dollars américains investis dans l’écosystème de conditionnement taïwanais, sur trois ans, avec ASE et SPIL comme partenaires centraux. Pour les architectes cloud de la zone DACH, il ne s’agit pas d’une histoire asiatique, mais d’un signal pour le second semestre.
26.05.2026
Les points clés en bref
- Double présence avant la Computex : Su est à Taïpeh depuis le 20.05 avec son annonce de 10 milliards, Huang y est arrivé le 24.05 avec un arrêt chez TSMC. Les deux PDG sont présents une semaine avant la plus grande édition de la foire jusqu’à présent (1 500 exposants, quatre sites, du 2 au 5 juin).
- L’engagement d’AMD vise le conditionnement avancé : ASE et SPIL comme partenaires, Elevated-Fan-Out-Bridge (EFB) comme technologie. Cela répond précisément au goulot d’étranglement CoWoS auquel la chaîne d’approvisionnement de Nvidia fait face actuellement.
- Conséquence pour les équipes Cloud : Le volume Vera Rubin reste limité, les slots d’inférence deviennent plus chers, la gamme Instinct d’AMD devient une deuxième option sérieuse pour les achats du second semestre. Ceux qui n’avaient prévu que Nvidia en 2026 devraient élargir leur modèle de sourcing dès maintenant.
Similaire :AWS et Nvidia : le million de GPU pousse les équipes Platform / FinOps pour l’inférence IA
Ce qui s’est vraiment passé ce week-end à Taïpeh
Qu’est-ce que le conditionnement avancé ? Le conditionnement avancé décrit l’empilement et l’assemblage entre la puce logique et la mémoire haute bande passante, rendant ainsi une GPU IA moderne opérationnelle. CoWoS chez TSMC est la variante la plus connue, tandis que l’Elevated-Fan-Out-Bridge d’AMD en est la réponse. Celui qui dispose de cette capacité détermine le rythme de livraison de la prochaine génération de GPU.
L’enchaînement des événements explique le terrain de jeu. Su a placé l’engagement d’AMD dans la fenêtre où tous les regards se tournent naturellement vers Taïpeh. Huang est arrivé plus tard, mais avec le geste le plus marquant : un pèlerinage chez TSMC et une déclaration publique faisant de Vera Rubin le plus grand lancement de produit de l’histoire de l’île.
Chronologie de la semaine de la Computex
- Mer 20.05. : La PDG d’AMD, Lisa Su, arrive à Taïpeh. Le communiqué de relations investisseurs d’AMD annonce plus de 10 milliards de dollars d’investissements dans l’écosystème sur trois ans. Focus : conditionnement avancé avec ASE et SPIL.
- Jeu 21.05. : Reuters et CNBC vérifient l’étendue de l’investissement. Su visite TSMC pour clarifier la capacité 2 nanomètres.
- Sam 24.05. : Le PDG de Nvidia, Jensen Huang, atterrit à Taïpeh en après-midi. Première déclaration : Vera Rubin serait le plus grand lancement de produit de l’histoire de Taïwan.
- Dim-Lun 25.-26.05. : Huang visite TSMC pour coordonner la montée en puissance. Participation à Meet-a-Claw avec la communauté locale de développeurs.
- Lun 01.06. : Keynote GTC Taipei au Taipei Music Center, à 11 heures heure locale. La Computex démarre le 02.06. sur quatre sites à Taïpeh.
La source primaire pour le mouvement d’AMD est le communiqué de relations investisseurs du 20 mai. Il mentionne la technologie EFB et chiffre explicitément le volume sur trois ans. Qui ne voit là que du marketing sous-estime le point : AMD place les fonds là où Nvidia rencontre aujourd’hui le goulot d’étranglement.
Pourquoi l’engagement en matière de packaging déplace les lignes du jeu
CoWoS a été le goulot d’étranglement numéro un, nommément, dans la pile IA en 2024 et 2025. Les H100 et H200 de Nvidia, puis Blackwell, dépendaient tous de la capacité CoWoS de TSMC, car il est impossible de fixer proprement la mémoire haute bande passante (HBM) aux GPU sans packaging avancé. Ceux qui ont passé une commande GB200 il y a 18 mois n’ont toujours pas leur date de livraison.
L’investissement de 10 milliards d’Euros d’AMD ne vise pas la tranche de silicium (wafer), mais cette couche. ASE et SPIL sont les deux plus grands acteurs asiatiques de l’assemblage externalisé, Elevated-Fan-Out-Bridge (EFB) est la réponse maison d’AMD à CoWoS-L. Un délai d’exécution de trois ans ressemble à une planification stratégique majeure, pas à une réaction.
Parallèlement, Huang a clarifié le message de son coup : Vera Rubin serait le plus grand lancement produit de l’histoire de l’entreprise. C’est du langage marketing, mais cela repose sur un noyau dur : Nvidia lie la prochaine génération de GPU encore plus étroitement à la feuille de route de TSMC. AWS a rendu visible son engagement pour des millions de GPU il y a quatre jours et Microsoft, Meta et Google ont annoncé des volumes similaires pour 2026. Si la capacité de packaging reste serrée, le volume ira principalement aux hyperscalers, moins aux clusters de PME DACH.
Trois conséquences pour les architectes cloud DACH
La semaine de Computex n’est pas une nouvelle venue d’Asie pour les équipes plateformes européennes, mais un indicateur pour le second semestre.
Premièrement : les slots d’inférence restent rares. Ceux qui planifient la capacité d’inférence GPU au cours du deuxième semestre ne devraient pas compter sur une baisse des prix Spot. Les hyperscalers absorbent le volume, le marché secondaire pour l’inférence se rétrécit. L’enseignement FinOps des derniers mois reste valable : les réservations valent le coup, le paiement à la demande devient une solution de secours coûteuse.
Deuxièmement : AMD Instinct devient une position obligatoire dans le sourcing. Jusqu’à mi-2025, le MI300 d’AMD était souvent l’alternative « nice-to-have » pour les équipes cloud DACH. Avec l’engagement en packaging et la disponibilité du MI355X, la donne change. Ceux qui ont planifié exclusivement Nvidia pour 2026 devraient revoir leur modèle d’approvisionnement. Non par amour de la marque, mais parce que la sécurité d’approvisionnement devient le deuxième axe.
Troisièmement : l’architecture d’inférence devient plus importante que la prochaine génération de GPU. Si la pénurie persiste, la levier n’est pas le prochain briefing vendeur, mais votre propre layout d’inférence. La quantification, la stratégie KV-Cache, le routage par lots entre les régions cloud, tout cela a plus d’impact sur la facture qu’un passage de H200 à H100. Le Playbook d’inférence est un point de départ plus pratique qu’un nouveau contrat avec un hyperscaler.
Ce qui reste ouvert jusqu’à la keynote de lundi
Trois points ne sont pas clarifiés avant la keynote GTC Taipei du 1er juin. Premièrement, si Huang précise la disponibilité de Vera Rubin pour les régions hyperscalers DACH. Deuxièmement, si TSMC répond publiquement à l’engagement d’AMD en packaging, par exemple avec un chiffre propre d’expansion CoWoS. Troisièmement, si un OEM allemand franchit le pas lors de Computex lui-même et passe à un approvisionnement mixte Nvidia plus AMD.
Jusque-là, l’étape pragmatique pour les architectes cloud s’impose : examiner honnêtement le modèle de sourcing, traiter la stack d’inférence comme un levier de coûts, ne pas planifier la stratégie GPU comme un choix de marque.
Foire aux questions
Que signifie concrètement la double apparition de Su et Huang à la Computex pour les livraisons de GPU dans la région DACH ?
Rien à court terme. Beaucoup à moyen terme. Les hyperscalers accaparent la majeure partie de la capacité de packaging chez TSMC, et récemment aussi chez ASE et SPIL, jusqu’en 2026. Les équipes cloud de la région DACH qui souhaitent exploiter leurs propres serveurs GPU doivent prévoir des délais d’approvisionnement plus longs pour les GB200 et MI355X, et considérer la configuration mixte comme un plan A, et non comme un plan B.
AMD Instinct vaut-il déjà le coup aujourd’hui en tant que plateforme d’inférence ?
Pour de nombreuses charges de travail d’inférence, oui. Les MI300 et MI355X offrent des tokens par seconde et par dollar compétitifs dans les scénarios limités par la bande passante mémoire. Le fossé logiciel par rapport à CUDA se comble lentement : ROCm 7 couvre aujourd’hui la plupart des piles logicielles LLM. Si vous utilisez déjà la quantification, vLLM ou TGI, vous pouvez tester AMD de manière réaliste dès aujourd’hui.
Quelle est la différence entre CoWoS et Elevated Fan-Out Bridge ?
CoWoS place les dies sur un interposeur en silicium, tandis que l’EFB utilise des structures de pont pour connecter le die logique aux piles HBM. Point pertinent pour l’architecte : l’EFB évolue différemment en termes de surface et soulage les goulots d’étranglement de TSMC liés au CoWoS classique. Si l’approche d’AMD tient les promesses de son investissement, une deuxième source de packaging indépendante verra le jour pour la première fois en 2027.
Comment les architectes cloud doivent-ils désormais adapter leur planification des achats pour le second semestre ?
Premièrement, ne pas miser uniquement sur Nvidia pour les réservations de GPU, mais intégrer les SKU AMD dans le modèle d’approvisionnement. Deuxièmement, analyser les charges de travail d’inférence pour identifier celles qui sont limitées par la bande passante plutôt que par la puissance de calcul, car c’est là que réside l’avantage d’AMD. Troisièmement, verrouiller les fenêtres de réservation auprès des hyperscalers pour les troisième et quatrième trimestres, avant que les annonces de la Computex n’attisent davantage la demande.
Quelle keynote de la Computex un architecte cloud devrait-il suivre en direct le 1er juin ?
La keynote GTC Taipei de Jensen Huang à 11 h, heure de Taipei. Deux éléments y seront déterminants : une date de livraison concrète pour Vera Rubin sera-t-elle annoncée pour les régions d’hyperscalers hors des États-Unis ? Et y aura-t-il des précisions sur la couche logicielle, notamment sur la manière dont CUDA et NIM se positionnent face à ROCm et Triton ? Ces deux aspects influenceront directement les décisions architecturales du troisième trimestre.
Plus de contenus du réseau MBF Media
Plus du réseau MBF Media
MyBusinessFutureQuand la productivité IA devient coûteuse : le coût de la consolidation des outilsDigital ChiefsMicrosoft AI-ARR : 37 Mrd. Dollar, ce que les résultats du Q1 impliquent pour les budgets des DSI de la région DACHSecurityTodayTrapDoor : attaque coordonnée sur la chaîne d’approvisionnement ciblant npm, PyPI et CratesSource de l’image : Pexels / panumas nikhomkhai (px:37730212)
